Bayesian statistics resources
In class session 2 (see this from the FAQ slides) we talked briefly about the difference between frequentist statistics, where you test for the probability of your data given a null hypothesis, or \(P(\text{data} \mid H_0)\), and Bayesian statistics, where you test for the probability of your hypothesis given your data, or \(P(H \mid \text{data})\).
This difference is important. In the world of frequentism, which is what pretty much all statistics classes use (including this one!), you have to compare your findings to a hypothetical null world and you have to talk about rejecting null hypotheses. In the Bayes world, though, you get to talk about the probability that your hypothesis is correct rather than the probability of seeing a value in a null world. So much more convenient and easy to interpret!
Bayesian statistics, though, requires a lot of computational power and a different way of thinking about statistics and numbers in general. And very few classes teach it. Including this one! I use Bayesian stats all the time in my own research (see this or this, for instance), but don’t teach it (yet!) because nobody else really teaches it and frequentist statistics still rule the policy world, so you need to know it.
Resources
But you can learn it on your own. Because very few stats classes actually teach Bayesian statistics, tons of people who use it are self-taught (like me!), in part because there are a ton of resources online for learning this stuff. Here are some of the best I’ve found:
- This new Bayes Rules book is designed to be an introductory textbook for a stats class teaching Bayesian stuff. It’s really accessible and good (and free!). If I ever get to teach an intro stats class with Bayesian stats, I’ll use this.
- This post from 2016 is a great short introduction and is what made me start using Bayesian methods. The brms package makes it incredibly easy to do Bayesian stuff, and the syntax is basically the same as
lm() - This post shows how to do one simple task (a difference-in-means test) with regular old frequentist methods, bootstrapping, and with Bayesian stats both with brms and raw Stan code
- This short post gives a helpful overview of the intuition behind Bayesianism
- The super canonical everyone-has-this-book book is Statistical Rethinking by Richard McElreath. At that page he also has an entire set of accompanying lectures on YouTube. He doesn’t use brms or ggplot, but someone has translated all his models to tidyverse-based brms code here
- The Theory That Would Not Die is a fun little general introduction to the history of Bayesianism and why it kind of disappeared in the 20th century and was replaced by frequentism and p-values and null hypothesis testing
Super short example
In practice, the R code for Bayesian models should be very familiar. For instance, here’s a regular old frequentist OLS model:
library(tidyverse)
library(broom)
model_ols <- lm(hwy ~ displ + drv, data = mpg)
tidy(model_ols, conf.int = TRUE)
## # A tibble: 4 × 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 30.8 0.924 33.4 4.21e-90 29.0 32.6
## 2 displ -2.91 0.218 -13.4 1.73e-30 -3.34 -2.48
## 3 drvf 4.79 0.530 9.05 6.40e-17 3.75 5.83
## 4 drvr 5.26 0.734 7.17 1.03e-11 3.81 6.70
Here’s that same model using the brms package, with default priors. Note how the code is basically the same:
library(tidyverse)
library(brms) # For Bayesian regression with brm()
library(broom.mixed) # For tidy() and glance() with brms-based models
library(tidybayes) # For extracting posterior draws
# This will take a few seconds to run
model_bayes <- brm(hwy ~ displ + drv, data = mpg)
tidy(model_bayes)
## # A tibble: 5 × 8
## effect component group term estimate std.error conf.low conf.high
## <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 fixed cond <NA> (Intercept) 30.8 0.922 29.0 32.6
## 2 fixed disp <NA> displ -2.91 0.219 -3.32 -2.48
## 3 fixed cond <NA> drvf 4.80 0.525 3.76 5.83
## 4 fixed cond <NA> drvr 5.25 0.754 3.79 6.75
## 5 ran_pars cond Residual sd__Observation 3.10 0.149 2.81 3.41
In Bayes land, you get a distribution of plausible values given the data (or what is called the “posterior distribution”), and you can visualize this posterior distribution:
# Make a long dataset of the draws for these three coefficients
posterior_draws <- model_bayes %>%
gather_draws(c(b_displ, b_drv, b_drvf, b_drvr))
# Plot this thing
ggplot(posterior_draws, aes(x = .value, y = fct_rev(.variable), fill = .variable)) +
geom_vline(xintercept = 0) +
stat_halfeye(.width = c(0.8, 0.95), alpha = 0.8, point_interval = "median_hdi") +
guides(fill = "none") +
labs(x = "Coefficient", y = "Variable",
caption = "80% and 95% credible intervals shown in black")
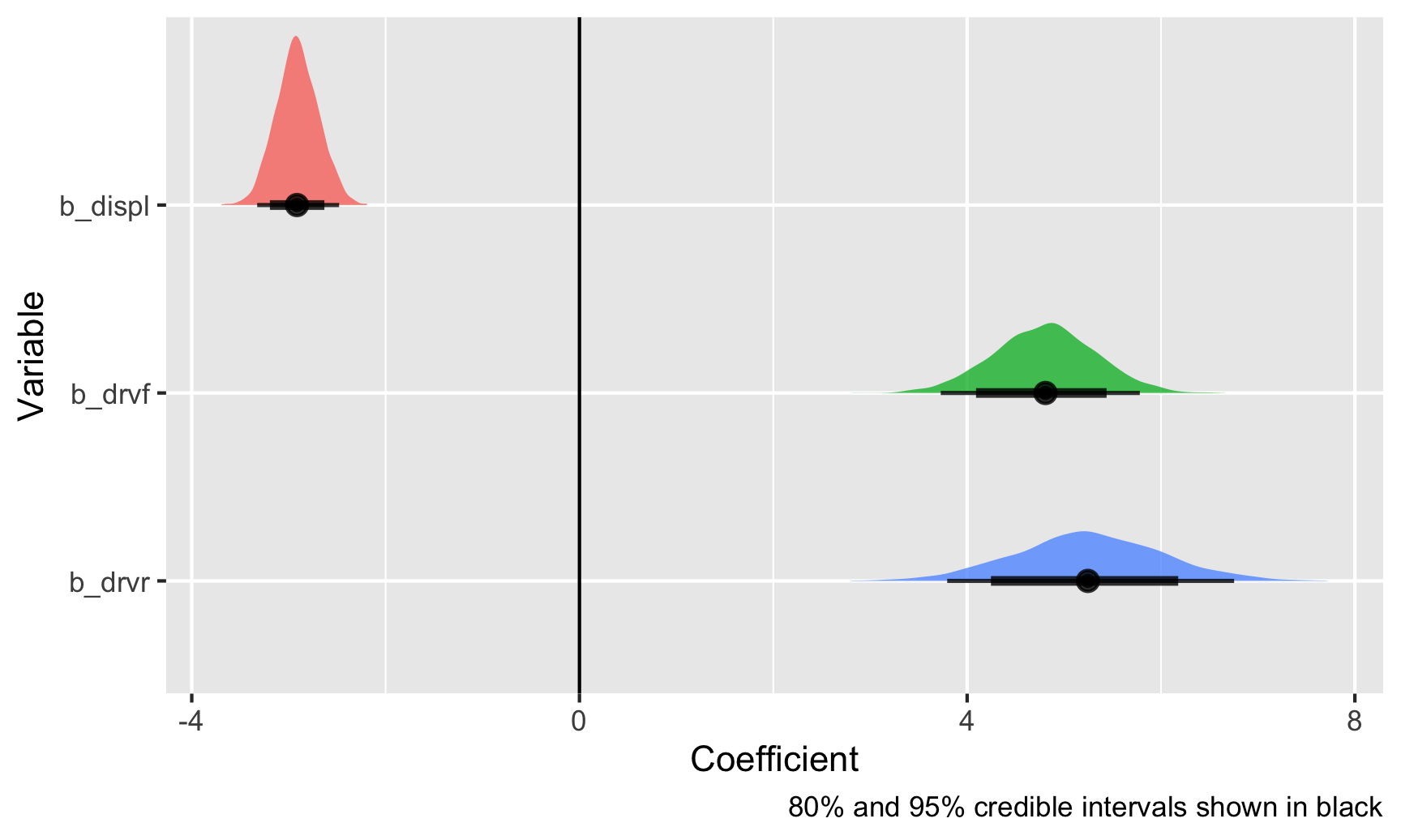
Those are all the plausible values for these coefficients, given the data that we’ve fed the model, and the black bars at the bottom show the 80% and 95% credible intervals (or the range of values that 80/95% of the posterior covers). With this, there’s a 95% chance that the coefficient for displacement is between −3.35 and −2.48. Neat!
Confidence intervals vs. credible intervals
In session 6, we talked about frequentist confidence intervals and Bayesian credible (or posterior) intervals, since I had you read Guido Imbens’s essay on p-values, where his conclusion is that:
It would be preferable if reporting standards emphasized confidence intervals or standard errors, and, even better, Bayesian posterior intervals.
Imbens wants us to use Bayesian posterior intervals (or credible intervals), but how do we do that?
Frequentist confidence intervals
In frequentist statistics (i.e. all the statistics you’ve been exposed to in this class and all previous classes), your whole goal is to estimate and infer something about a population using a sample. This “something” is a true (but unknown) thing called a population parameter. It is a single fixed value that exists out in the world, and it’s the main thing you’re interested in discovering. Here are a bunch of different population parameters:
- Average treatment effect of a program
- Proportion of left-handed students at GSU
- Median rent of apartments in NYC
- Proportion of red M&Ms produced in a factory
In frequentist statistics, we take a sample from the population, calculate the parameter (i.e. mean, median, proportion, whatever) in the sample, and then check to see how good of a guess it might be for the whole population. To do that, we can look at a confidence interval. Think of a confidence interval as a net—it’s a range of possible values for the population parameters, and we can be X% confident (typically 95%) that the net is picking up the population parameter. Another way to think about it is to imagine taking more samples. If you take 100 samples, at least 95 of them would have the true population parameter in their 95% confidence intervals. Frequentist statistics assumes that the unknown population parameter is fixed and singular, but that the data can vary—you can repeat an experiment over and over again, or take repeated samples from a population in order to be more certain about the estimate of the parameter (and shrink the net of the confidence interval).
Importantly, when talking about confidence intervals, you cannot really say anything about the estimate of the parameter itself. Confidence intervals are all about the net, or the range itself. You can legally say this:
We are 95% confident that this confidence interval captures the true population parameter.
You cannot say this:
There’s a 95% chance that the population parameter is X. or There’s a 95% chance that the true value falls in this range.
Confidence intervals tell you about the range, or the net. That’s all.
Here’s an example with some data from The Effect on restaurant inspections in Alaska. We want to know if weekend inspections are more lenient that ones conducted during the work week.
library(tidyverse)
library(broom)
library(gghalves)
inspections <- read_csv("https://vincentarelbundock.github.io/Rdatasets/csv/causaldata/restaurant_inspections.csv")
First we should look at the data to see if there are any obvious patterns. Let’s look at scores separated by weekend status. We’ll use the neat gghalves package to plot both the raw points and a density plot. The orange points show the average value:
ggplot(inspections, aes(x = Weekend, y = inspection_score)) +
geom_half_point(side = "l", alpha = 0.2, size = 0.5,
transformation = position_jitter(height = 0)) +
geom_half_violin(side = "r") +
stat_summary(fun.data = "mean_se", fun.args = list(mult = 1.96), color = "orange")
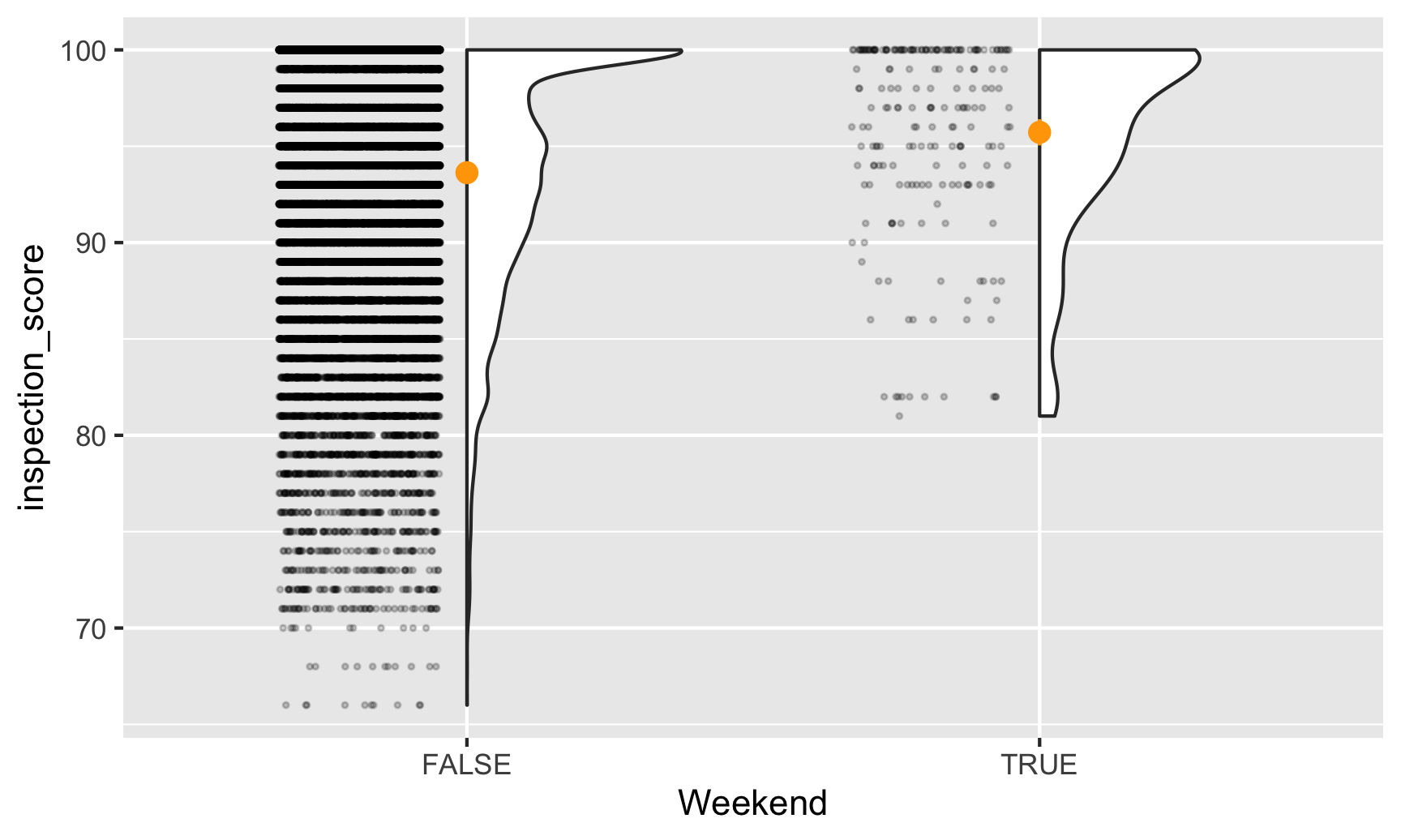
It looks like weekend inspections are far more rare than weekday ones, and no weekend inspections every give scores lower than 80. It also looks like the average weekend score is slightly higher than the average weekday score. Let’s figure out how much of a difference there is.
But first, we’ll use the language of inference and sampling. Our population parameter (we’ll call it the Greek letter theta, or \(\theta\)) is some single true fixed number that exists out in the world—weekend restaurant inspections in Alaska have a \(\theta\) higher average score than weekday inspections. We want to find out what that \(\theta\) is, so we’ll look at some confidence intervals.
We can look at a basic difference in means based on weekend status:
model_naive <- lm(inspection_score ~ Weekend,
data = inspections)
tidy(model_naive, conf.int = TRUE)
## # A tibble: 2 × 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 93.6 0.0381 2458. 0 93.6 93.7
## 2 WeekendTRUE 2.10 0.433 4.84 0.00000131 1.25 2.95
Here, weekend scores are 2.1 points higher than weekday scores, on average (that’s our estimate, or \(\hat{\theta}\). We have a confidence interval of 1.2–2.9. We cannot say that we’re 95% confident that the weekend score boost (or \(\theta\)) is between 1.2 and 2.9. What we can say is that we’re 95% confident that the range 1.2–2.9 captures the true population parameter \(\theta\). If we took a bunch of different samples of inspection scores and calculated the average weekend vs. weekday score in each of those samples, 95% of those confidence intervals should capture the true \(\theta\). Importantly, we still have no idea what the actual \(\theta\) is, but we’re pretty sure that our confidence interval net has captured it.
This estimate is probably wrong, since there are other factors that confound the weekend → score relationship. Maybe the health department only conducts weekend inspections in places with lots of branches, or maybe they did more weekend inspections in certain years. We can adjust/control for these in the model:
model_adjusted <- lm(inspection_score ~ Weekend + NumberofLocations + Year,
data = inspections)
tidy(model_adjusted, conf.int = TRUE)
## # A tibble: 4 × 7
## term estimate std.error statistic p.value conf.low conf.high
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 225. 12.4 18.1 7.88e-73 200. 249.
## 2 WeekendTRUE 1.43 0.419 3.42 6.25e- 4 0.611 2.25
## 3 NumberofLocations -0.0191 0.000436 -43.9 0 -0.0200 -0.0183
## 4 Year -0.0646 0.00617 -10.5 1.45e-25 -0.0767 -0.0525
Our weekend estimate shrunk a little and is now 1.43, with a confidence interval of 0.6–2.3. Again, think of this as a net—we’re 95% sure that the true \(\theta\) is in that net somewhere. \(\theta\) could be 0.7, it could be 1.4, it could be 2.2—who knows. All we know is that our net most likely picked it up.
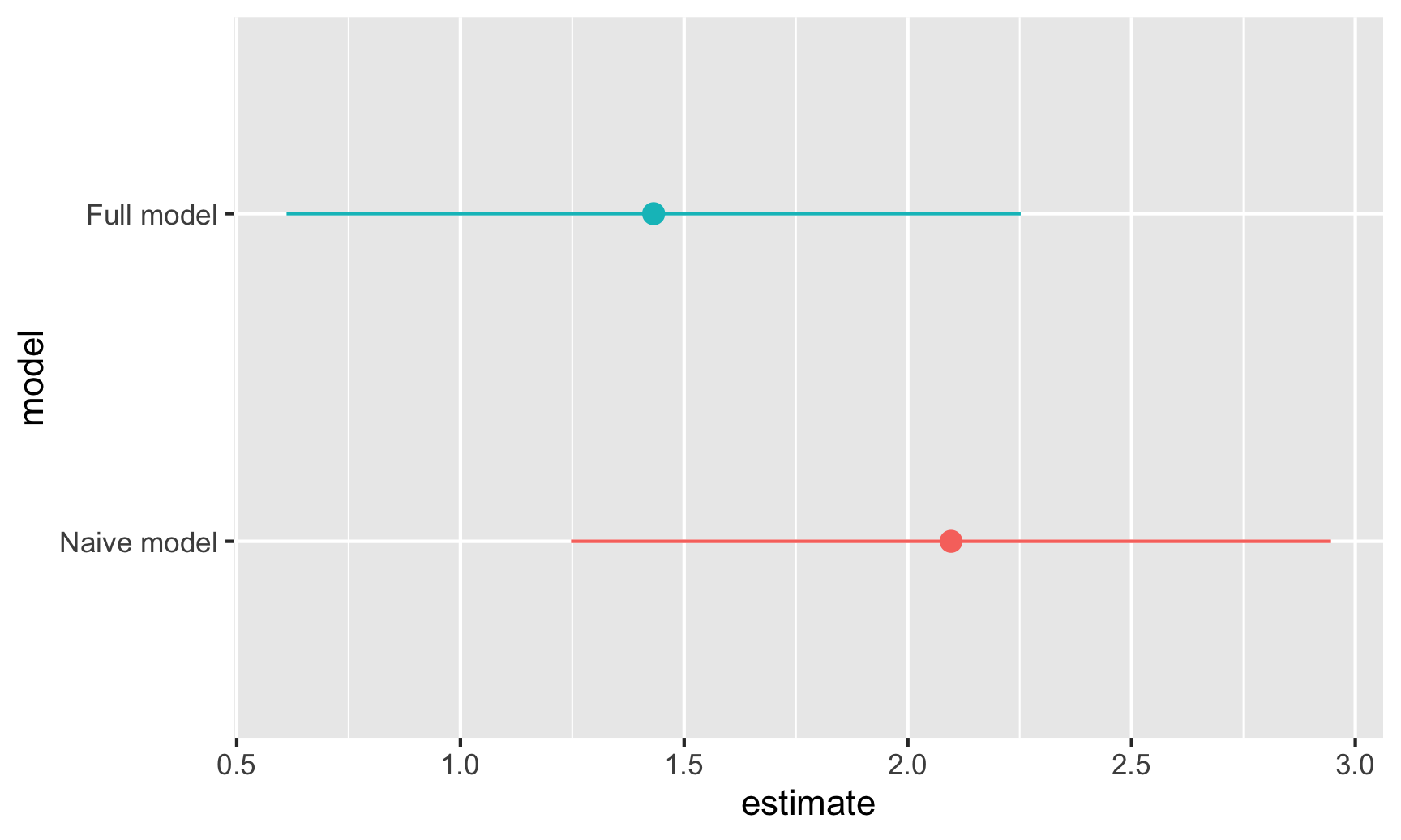
For fun, let’s plot both these weekend estimates and their confidence intervals:
# Save just the weekend coefficient from both models
freq_results_naive <- tidy(model_naive, conf.int = TRUE) %>%
mutate(model = "Naive model") %>%
filter(term == "WeekendTRUE")
freq_results_full <- tidy(model_adjusted, conf.int = TRUE) %>%
mutate(model = "Full model") %>%
filter(term == "WeekendTRUE")
# Put these coefficients in a single dataset and plot them
freq_results <- bind_rows(freq_results_naive, freq_results_full) %>%
# Make sure the model name follows the order it appears in the data instead of
# alphabetical order
mutate(model = fct_inorder(model))
ggplot(freq_results, aes(x = estimate, y = model, color = model)) +
geom_pointrange(aes(xmin = conf.low, xmax = conf.high)) +
guides(color = "none")
Bayesian credible intervals
Remember, with frequentist statistics, \(\theta\) is fixed and singular and we’re hoping to pick it up with our confidence interval nets. The data we collect is variable—we can hypothetically take more and more samples and calculate a bunch of confidence intervals and become more certain about where \(\theta\) might be. We can only interpret confidence intervals as ranges: “There’s a 95% probability that the range contains the true value \(\theta\)”. We can’t say anything about the estimate of \(\theta\) itself. We’ve calculated the probability of the range, not the probability of the actual value.
Bayesian analysis, however, does let us talk about the probability of the actual value. Under Bayesianism, the data you’re working with is fixed (i.e. you collected it once and it’s all you have—you can’t go out and collect infinite additional samples), and the population parameter \(\theta\) varies and has uncertainty about it (i.e. instead of imagining some single number uncapturable that’s the average difference in weekend vs. weekday scores, \(\theta\) has some range around it).
This difference is apparent in the formulas for testing hypotheses under each of these approaches:
$$\underbrace{P(\text{Data} \mid \theta)}_{\substack{\textbf{Frequentism} \\ \text{Probability of seeing the} \\ \text{data given that } \theta \text{ exists}}} \qquad \underbrace{P(\theta \mid \text{Data})}_{\substack{\textbf{Bayesianism} \\ \text{Probability of } \theta \\ \text{given the current data}}}$$
Bayes' theorem has a nice formula (with neat intuition, like in this video):
$$ \underbrace{P(\theta \mid \text{Data})}_{\text{Posterior}} = \frac{\overbrace{P(\theta)}^{\text{Prior}} \times \overbrace{P(\text{Data} \mid \theta)}^{\text{Likelihood}}}{P(\text{Data})} $$
Put (hopefully!) simply, combine the observed likelihood of the data \(P(\text{Data} \mid \theta)\) (that’s basically frequentism!) with prior knowledge about the distribution of \(\theta\) and you’ll get a posterior estimate of \(\theta\).
Actually calculating this with real data, though, can be tricky and computationally intensive—often there’s no formal mathematical way to figure out the actual equation. So instead, we can use computers to simulate thousands of guesses and then look at the distribution of those guesses (just like we did with the Zilch simulation in class). One modern method for doing this is called Monte Carlo Markov Chain (MCMC) simulation, which is what most R-based tools for Bayesian stats use nowadays.
Let’s look at restaurant inspection scores on the weekend Bayesianly. Here, we’re still interested in our population parameter \(\theta\), or the average weekend score boost. Only now, we’re not assuming that \(\theta\) is some single fixed value out in the world that we’re trying to capture with confidence intervals—we’ll use the data that we have to estimate the variation in \(\theta\). The easiest way to do Bayesian analysis with R is with the brms package, which uses the familiar formula syntax you’ve been using with lm(). The syntax is super similar, just with a few additional arguments:
MCMC things
Arguments like chains, iter, and cores deal with the simulation. chains defines how many parallel simulations should happen, iter controls how many iterations should happen with in each chain, and cores spreads those chains across the CPUs in your computer (i.e. if you have a 4-core computer, you can run 4 chains all at the same time; run parallel::detectCores() in your R console to see how many CPU cores you have). seed makes it so that the random simulation results are reproducible (see here for more on seeds).
Priors
These define your prior beliefs about the parameters (i.e. \(\theta\)) in the model. If you think that the restaurant weekend inspection boost is probably positive, but could possibly be negative, or maybe zero, you can feed that belief into the model. For instance, if you’re fairly confident (based on experiences in other states maybe) that weekend scores really are higher, you can provide an informative prior that says that \(\theta\) is most likely 1.5 points ± a little variation, following a normal distribution. Or, if you have no idea what it could be—maybe it’s super high like 10, maybe it’s negative like −5, or maybe it’s 0 and there’s no weekend boost—you can provide a vague prior that says that \(\theta\) is 0 points ± a ton of variation.
library(patchwork) # For combining ggplot plots
plot_informative <- ggplot() +
stat_function(fun = dnorm, args = list(mean = 1.5, sd = 0.5),
geom = "area", fill = "grey80", color = "black") +
xlim(-1, 4) +
labs(title = "Informative prior", subtitle = "Normal(mean = 1.5, sd = 0.5)",
caption = "We're pretty sure θ is around 1.5")
plot_vague <- ggplot() +
stat_function(fun = dnorm, args = list(mean = 0, sd = 10),
geom = "area", fill = "grey80", color = "black") +
xlim(-35, 35) +
labs(title = "Vague prior", subtitle = "Normal(mean = 0, sd = 10)",
caption = "Surely θ is in there *somewhere*")
plot_informative | plot_vague
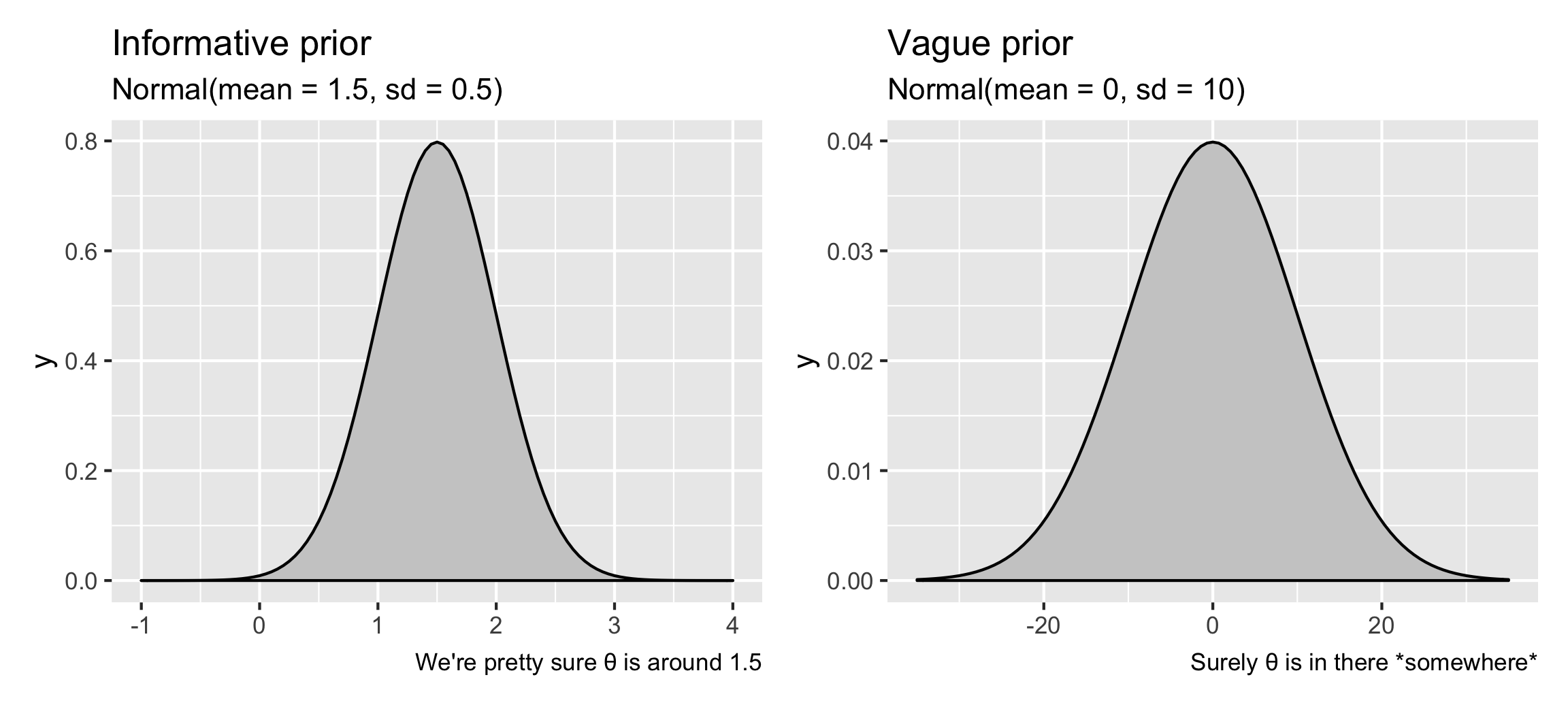
For the sake of this example, we’ll use a vague prior.
Here’s how to officially do Bayesian analysis with brms and incorporate prior information about \(\theta\). Again, the syntax is super similar to lm(), just with some extra bits about the prior and the MCMC settings:
library(brms) # For Bayesian regression with brm()
library(broom.mixed) # For tidy() and glance() with brms-based models
library(tidybayes) # For extracting posterior draws
library(ggdist) # For making pretty posterior plots
# bf() stands for "bayes formula"; you technically don't need to use it, but it
# makes life easier for more complex models, so it's good practice even when
# using a simple formula like the one here
#
# This will take a little bit of time to run. Here's what it's actually doing:
#
# 1. Translate this R code to Stan (a specific language for doing Bayesian stuff with MCMC)
# 2. Compile the Stan code to faster-running C++ code
# 3. Actually do the MCMC sampling
# Set the prior for the weekend coefficient
# Use get_priors() to see all the other default priors
priors <- c(
prior(normal(0, 10), class = "b", coef = "WeekendTRUE")
)
# Run the model!
model_bayes <- brm(bf(inspection_score ~ Weekend + NumberofLocations + Year),
data = inspections,
prior = priors,
chains = 4, iter = 2000, cores = 4, seed = 1234)
## Compiling Stan program...
## Start sampling
Phew. That took a while to run, but it ran! Now we can check the results:
tidy(model_bayes, conf.int = TRUE)
## # A tibble: 5 × 8
## effect component group term estimate std.error conf.low conf.high
## <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 fixed cond <NA> (Intercept) 224. 12.5 200. 249.
## 2 fixed cond <NA> WeekendTRUE 1.44 0.420 0.613 2.25
## 3 fixed cond <NA> NumberofLocations -0.0191 0.000428 -0.0200 -0.0183
## 4 fixed cond <NA> Year -0.0644 0.00624 -0.0765 -0.0522
## 5 ran_pars cond Residual sd__Observation 6.04 0.0252 5.99 6.09
Our estimate for the weekend boost, or \(\hat{\theta}\), is 1.44, which is basically the same as the frequentist estimate we found before. We have an interval too, but it’s not a confidence interval—it’s a credible interval. Instead of telling us about the range of the confidence interval net, this credible interval tells us the probability that \(\hat{\theta}\) falls in that range. It’s essentially the probability of the actual value, not the probability of the range. Based on this, there’s a 95% chance that—given the data we have—the weekend score boost ($\hat{\theta}$) is between 0.61 and 2.25.
We can visualize this posterior distribution to see more information than we could with our frequentist estimate. Remember, our simulation estimated thousands of possible coefficients for WeekendTRUE, and each of them are equally likely. The value that we see in tidy() is the median of all these simulated coefficients, or draws. We can see a few of them here:
model_bayes %>%
spread_draws(b_WeekendTRUE) %>%
head(10)
## # A tibble: 10 × 4
## .chain .iteration .draw b_WeekendTRUE
## <int> <int> <int> <dbl>
## 1 1 1 1 0.923
## 2 1 2 2 1.30
## 3 1 3 3 1.11
## 4 1 4 4 0.917
## 5 1 5 5 1.54
## 6 1 6 6 1.33
## 7 1 7 7 1.21
## 8 1 8 8 1.39
## 9 1 9 9 1.79
## 10 1 10 10 1.09
Sometimes the weekend boost is 1.2, sometimes 1.7, sometimes 1.3, etc. There’s a lot of variation in there. We can plot all these simulated coefficients to see where they mostly cluster:
weekend_draws <- model_bayes %>%
spread_draws(b_WeekendTRUE)
ggplot(weekend_draws, aes(x = b_WeekendTRUE)) +
stat_halfeye() +
labs(caption = "Point shows median value;\nthick black bar shows 66% credible interval;\nthin black bar shows 95% credible interval")
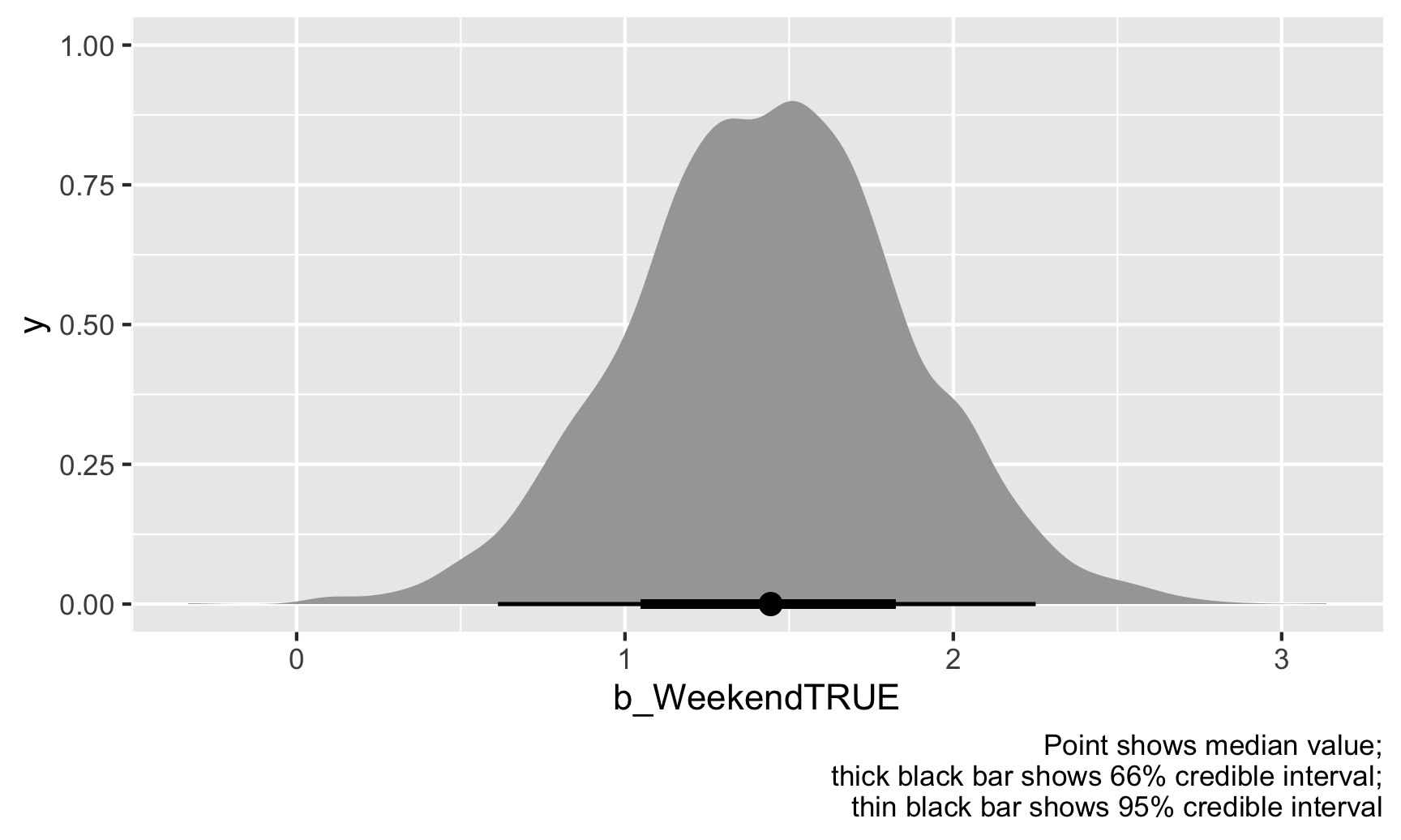
The weekend point boost \(\hat{\theta}\) is mostly clustered around 1–2, and 95% of those draws are between 0.61 and 2.25. We’re thus 95% sure that the actual weekend point boost is between 0.61 and 2.25 with a median of 1.44.
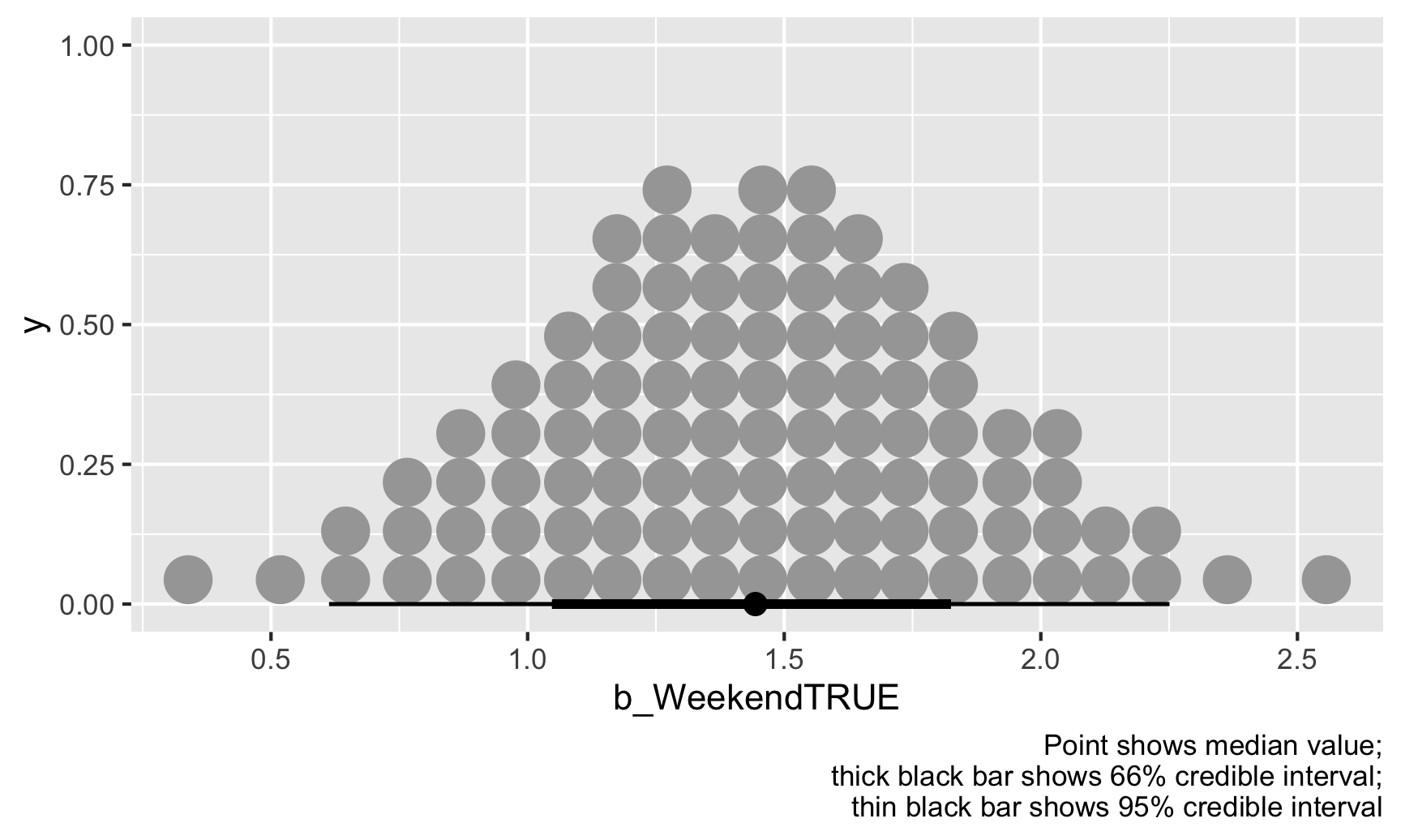
We can also look at this distribution a slightly different way by collapsing all those posterior draws into 100 possible values. Each of these dots is equally likely, and the true value of \(\theta\) could be any of them, but again, most are clustered around 1.44:
ggplot(weekend_draws, aes(x = b_WeekendTRUE)) +
stat_dotsinterval(quantiles = 100) +
labs(caption = "Point shows median value;\nthick black bar shows 66% credible interval;\nthin black bar shows 95% credible interval")
General summary of intervals
So, we’ve seen two different philosophies for quantifying uncertainty with confidence intervals and credible intervals. Here’s a general overview of the two approaches and how you can interpret them:
| Frequentism | Bayesianism | |
|---|---|---|
| Approach | \(P(\text{Data} \mid \theta)\) | \(P(\theta \mid \text{Data})\) |
| \(\theta\) is a fixed single value; data is variable and can be repeatedly sampled | \(\theta\) is variable and has uncertainty; data is fixed (you only have one sample) | |
| How to do it in R | lm(...) |
library(brms)brm(...) |
| Name | Confidence interval | Credible interval (or posterior interval) |
| Intuition | Probability of the range | Probability of the actual value |
| Interpretation template | There's a 95% probability that this range contains the true value of \(\theta\) | There's a 95% probability that the true value of \(\theta\) falls in this range. |
| Few people naturally think like this | People do naturally think like this |
Two ways of making decisions with posterior distributions
In the world of frequentism, we’re interested in whether coefficients are statistically different from 0 in a null world where there’s no effect. We rely on p-values to see the probability of seeing an estimate at least as large as what we’ve calculated in a hypothetical world where that estimate is actually 0. This is a really non-intuitive way of thinking about the world (imaginary null worlds?!), so everyone always misinterprets p-values.
Remember what you read in Imbens’s article though—in real life, very few people care about whether a coefficient is significantly different from a hypothetical null. Instead, people want to know how certain you are of the estimate and what it means practically. Is it for sure a positive effect, or could it maybe be zero or maybe be negative? Significance stars can’t tell us much about those questions, but posterior Bayesian intervals can.
Probability of direction
One question we can answer with Bayesian results is “How certain are we that this estimate is positive (or negative)?” Are we sure the weekend scores are higher on average, or could they sometimes be negative? Are we sure that the average treatment effect of your program decreases poverty, or could it maybe have a positive effect instead?
To figure this out, we can calculate something called the “probability of direction," or the proportion of posterior draws that are above (or below) some arbitrary number. For instance, what’s the probability that the weekend boost is positive (or greater than 0)?
# Find the proportion of posterior draws that are bigger than 0
weekend_draws %>%
summarize(prop_greater_0 = sum(b_WeekendTRUE > 0) / n())
## # A tibble: 1 × 1
## prop_greater_0
## <dbl>
## 1 1.00
Whoa. 99.9% of the posterior draws for the weekend boost are greater than 0, meaning that there’s a 99.9% chance that the coefficient is positive, given the data we have.
The neat thing about the probability of direction is that we can choose whatever value we want as the threshold. Let’s say the state health director wants to know if weekend scores are higher than weekday scores, but she’s fine with just a little boost (weekends are nice! inspectors are happier!). Pretend that she thinks an average difference of 1 or lower isn’t a big concern, but seeing a difference greater than 1 is a signal that weekend inspectors are maybe being too lenient. We can use 1 as our threshold instead:
# Find the proportion of posterior draws that are bigger than 1
weekend_draws %>%
summarize(prop_greater_0 = sum(b_WeekendTRUE > 1) / n())
## # A tibble: 1 × 1
## prop_greater_0
## <dbl>
## 1 0.855
Based on this, 84% of the draws are higher than 1, so there’s an 84% chance that the actual \(\theta\) is greater than 1. Notice how there’s no discussion of significance here—no alpha thresholds, no stars, no null worlds. We just have a probability that \(\hat{\theta}\) is above 1. We can even visualize it. Everything to the right of that vertical line at 1 is “significant” (but not significant with null worlds and stars).
ggplot(weekend_draws, aes(x = b_WeekendTRUE)) +
stat_halfeye(aes(fill_ramp = stat(x > 1)), fill = "red") +
scale_fill_ramp_discrete(from = "darkred", guide = "none") +
geom_vline(xintercept = 1) +
labs(caption = "Point shows median value;\nthick black bar shows 66% credible interval;\nthin black bar shows 95% credible interval")
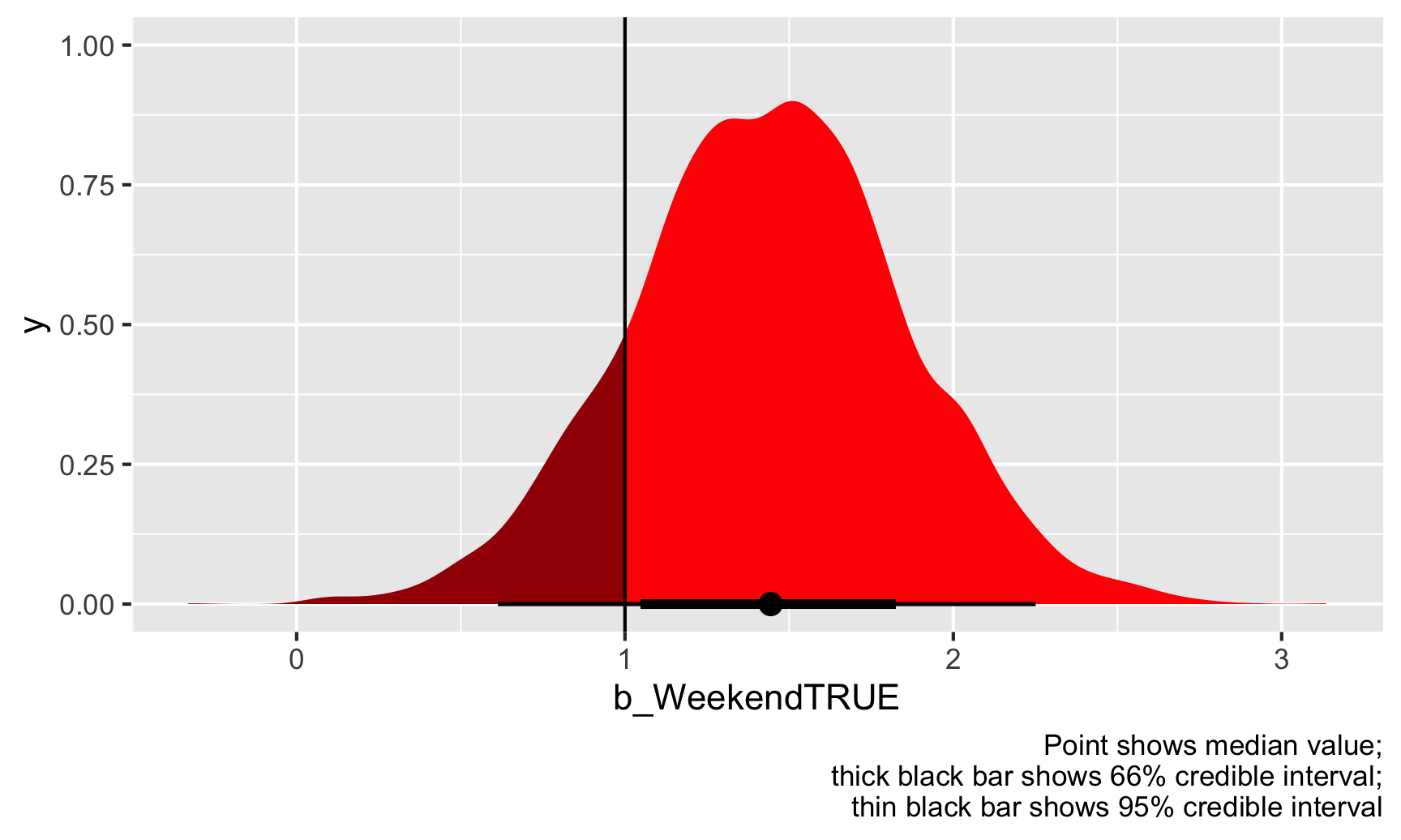
Should the state health director be concerned? Probably. There’s an 84% chance that weekend inspection scores are at least 1 point higher than weekday scores, on average, given the data we have.
Region of practical equivalence (ROPE)
Looking at the probability of direction is helpful if you are concerned whether an effect is positive or negative (i.e. greater or less than 0), but it’s also a little weird to think about because we’re testing if something is greater or less than some specific single number. In our example of the health director, we pretended that she cared whether the average weekend score was 1 point higher, but that’s arbitrary.
Another approach is that we can think of a range of \(\theta\) where there’s practically no effect. Think of this as a “dead zone” of sorts. If \(\hat{\theta}\) is 0, we know there’s no effect. If \(\hat{\theta}\) is something tiny like 0.2 or -0.3, we probably don’t actually care—that’s a tiny amount and could just be because of measurement error. It’s not anything really actionable. If \(\hat{\theta}\) is big like 1.3 or -2.4 or whatever, then we have cause to worry, but if the estimate is in the “dead zone” (however we want to define it), then we shouldn’t really care or worry.
The official Bayesian term for this “dead zone” is the region of practical equivalence (ROPE). There are lots of ways to determine this dead zone—you can base it on experience with the phenomenon (e.g., if you’re the health director and know a lot about inspection scores, you know what kind of score ranges matter), or you can base it on the data you have (e.g., -0.1 * sd(outcome) to 0.1 * sd(outcome)).
For this example, let’s pretend that the health director tells you that any effect between −0.5 and 0.5 doesn’t matter—for her, those kind of values would be the same as 0. Now that we have a dead zone or ROPE, we can calculate the proportion of coefficient draws that fall outside of that ROPE:
# Find the proportion of posterior draws that are bigger than 0.5 or less than -0.5
weekend_draws %>%
summarize(prop_outside_rope = 1 - sum(b_WeekendTRUE >= -0.5 & b_WeekendTRUE <= 0.5) / n())
## # A tibble: 1 × 1
## prop_outside_rope
## <dbl>
## 1 0.986
ggplot(weekend_draws, aes(x = b_WeekendTRUE)) +
stat_halfeye(aes(fill_ramp = stat(x >= 0.5 | x <= -0.5)), fill = "red") +
scale_fill_ramp_discrete(from = "darkred", guide = "none") +
annotate(geom = "rect", xmin = -0.5, xmax = 0.5, ymin = -Inf, ymax = Inf, fill = "purple", alpha = 0.3) +
annotate(geom = "label", x = 0, y = 0.75, label = "ROPE\n(dead zone)") +
labs(caption = "Point shows median value;\nthick black bar shows 66% credible interval;\nthin black bar shows 95% credible interval")
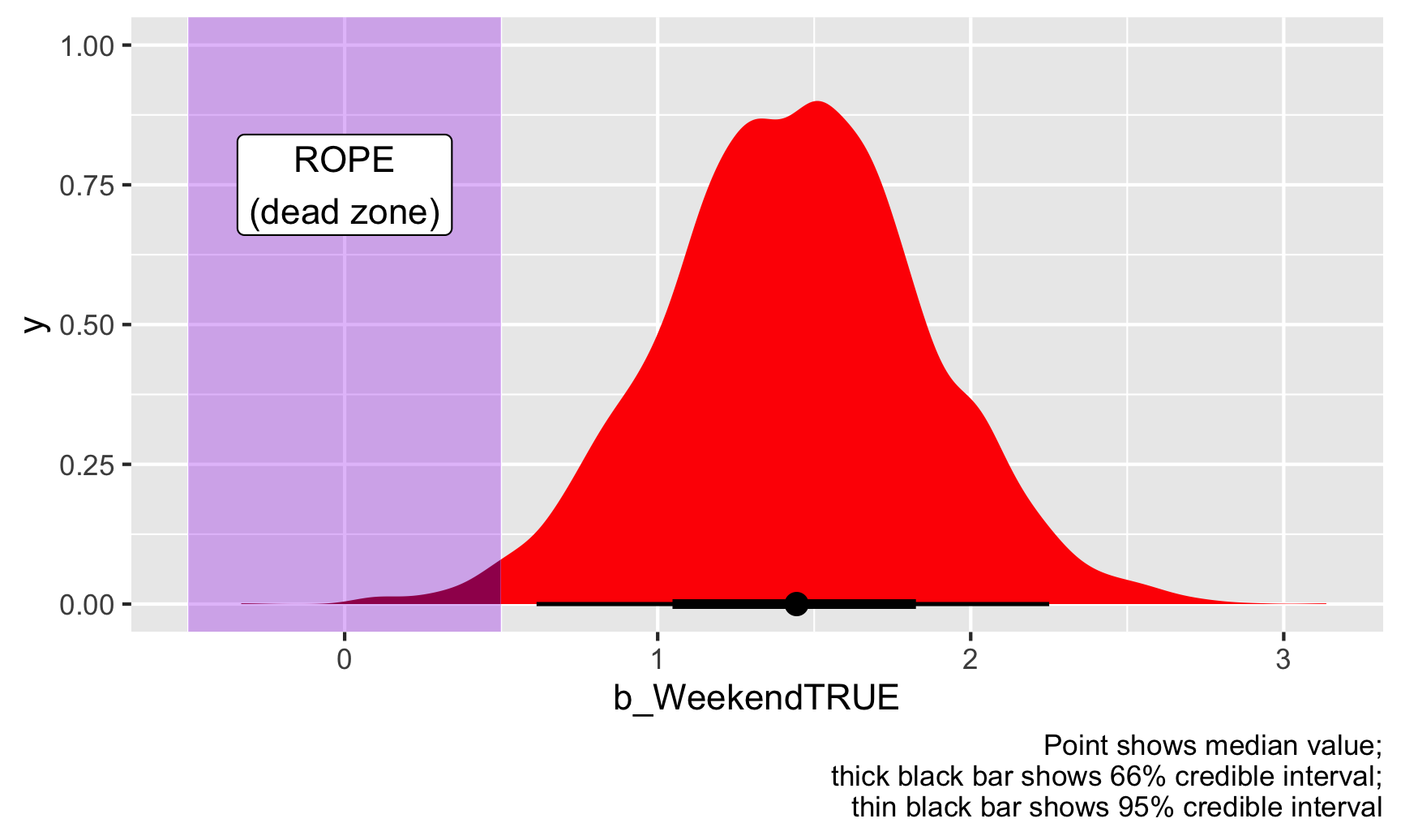
Given this data, 98% of the posterior distribution of the weekend boost is outside of the ROPE, or dead zone, so we can consider this to be “significant” (again, this is a tricky word because it has nothing to do with null worlds and stars!).
There are some debates over what you should check with the ROPE. Some people say that you should look at how much of the 95% credible interval is inside the dead zone; other say you should look at how much of the entire distribution is inside the dead zone. We just did the latter, with the whole distribution. If we want to see how much of the area within the credible interval is inside the dead zone, we can change the code a little to filter those observations out:
# Extract the 95% confidence interval range
weekend_cred_int <- weekend_draws %>%
median_hdi()
weekend_cred_int$.lower
## [1] 0.66
# Find the proportion of posterior draws that are bigger than 0.5 or less than
# -0.5, but only look inside the 95% credible interval
weekend_draws %>%
# Only look inside the credible interval
filter(b_WeekendTRUE >= weekend_cred_int$.lower & b_WeekendTRUE <= weekend_cred_int$.upper) %>%
summarize(prop_outside_rope = 1 - sum(b_WeekendTRUE >= -0.5 & b_WeekendTRUE <= 0.5) / n())
## # A tibble: 1 × 1
## prop_outside_rope
## <dbl>
## 1 1
If we look only at the 95% credible interval of the posterior, there’s a 0% chance that any of those estimated coefficients are in the dead zone / ROPE. There’s a 100% chance that the credible interval doesn’t touch the ROPE. You can see this visually too—look at the figure above with the purple ROPE. The thin black bar that shows the 95% credible interval doesn’t show up in the purple area.
Which approach is better—using full distribution or just using the credible interval? Who knows. That’s up to you.
Finally, here we decided on the ROPE kind of arbitrarily as −0.5 to 0.5, but there are more systematic ways of doing it. One common and standard suggestion is to use −0.1 and 0.1 times the standard deviation of the outcome variable:
c(-0.1, 0.1) * sd(inspections$inspection_score)
## [1] -0.63 0.63
Based on this approach, our ROPE/dead zone should be −0.63 to 0.63. Let’s see how that looks:
# Find the proportion of posterior draws that are bigger than 0.5 or less than
# -0.5, but only look inside the 95% credible interval
weekend_draws %>%
# Only look inside the credible interval
filter(b_WeekendTRUE >= weekend_cred_int$.lower & b_WeekendTRUE <= weekend_cred_int$.upper) %>%
summarize(prop_outside_rope = 1 - sum(b_WeekendTRUE >= -0.63 & b_WeekendTRUE <= 0.63) / n())
## # A tibble: 1 × 1
## prop_outside_rope
## <dbl>
## 1 1
ggplot(weekend_draws, aes(x = b_WeekendTRUE)) +
stat_halfeye(aes(fill_ramp = stat(x >= 0.63 | x <= -0.63)), fill = "red") +
scale_fill_ramp_discrete(from = "darkred", guide = "none") +
annotate(geom = "rect", xmin = -0.63, xmax = 0.63, ymin = -Inf, ymax = Inf, fill = "purple", alpha = 0.3) +
annotate(geom = "label", x = 0, y = 0.75, label = "ROPE\n(dead zone)") +
labs(caption = "Point shows median value;\nthick black bar shows 66% credible interval;\nthin black bar shows 95% credible interval")

This changes our results just a tiny bit. 97% of the full posterior distribution and 99.7% of the credible interval falls outside this ROPE. Neat. We can thus safely say that the weekend effect, or our estimate of \(\theta\) is definitely practical and substantial (or “significant” if we want to play with that language).